
Daftar Isi Artikel
- Ringkasan performa CodeGen 2025 berdasarkan benchmark yang kredibel
- Akurasi di benchmark vs ketahanan di produksi perusahaan
- Kecepatan, biaya, dan efisiensi token dalam keputusan bisnis
- Kalkulator Simulasi Menghitung Biaya CodeGen
- Kapasitas konteks dan kerja lintas repo
- Tooling resmi dan ekosistem, Codex, Claude Code, Gemini Code Assist
- Contoh Kode CodeGen untuk ChatGPT, Claude Opus 4.1, dan Gemini
- ChatGPT Codex, OpenAI Responses API (Python)
- ChatGPT Codex, OpenAI Responses API (JavaScript ESM)
- Anthropic Claude Opus 4.1, Messages API (Python)
- Anthropic Claude Opus 4.1, Messages API (JavaScript)
- Google Gemini 2.5 Pro, Generative AI API (Python)
- Google Gemini 2.5 Pro, Generative AI API (JavaScript)
- Metodologi Evaluasi dan Repro Guide untuk Perbandingan CodeGen
- Pemetaan Use Case ke Model CodeGen
- Failure Modes dan Debugging Guide
- Keamanan dan Tata Kelola yang Praktis
- Panduan Integrasi IDE, CLI, dan CI/CD
- Contoh Playbook Shadow Run 14 Hari yang Eksekutabel
- Roadmap Adopsi CodeGen di Tim Engineering Anda
Margabagus.com – Kode yang rapi bukan hanya urusan teknis, dampaknya terasa pada kecepatan rilis, biaya operasional, dan pengalaman pengguna akhir. Di banyak tim, bottleneck muncul pada tahap pengujian dan review, bukan di saat penulisan fungsi pertama. Itulah mengapa persaingan CodeGen 2025 mengerucut ke tiga nama besar, ChatGPT GPT-5, Claude Opus 4.1, dan Google Gemini 2.5, masing masing membawa pendekatan berbeda pada akurasi, konteks, dan orkestrasi alat. Benchmark publik seperti SWE-bench Verified digunakan untuk menilai kemampuan memperbaiki isu nyata, bukan sekadar menyelesaikan puzzle[10]. GPT-5 dikenal dengan jendela konteks ~400k dan jalur PR yang matang, Opus 4.1 dengan ketelitian tugas agentik multi langkah, dan Gemini 2.5 dengan integrasi IDE, CLI, serta GCP yang mulus[2][1][5][6]. Tujuan saya sederhana, membantu Anda memilih model andalan dan menyiapkan playbook uji yang bisa dipertanggungjawabkan.
Ringkasan performa CodeGen 2025 berdasarkan benchmark yang kredibel
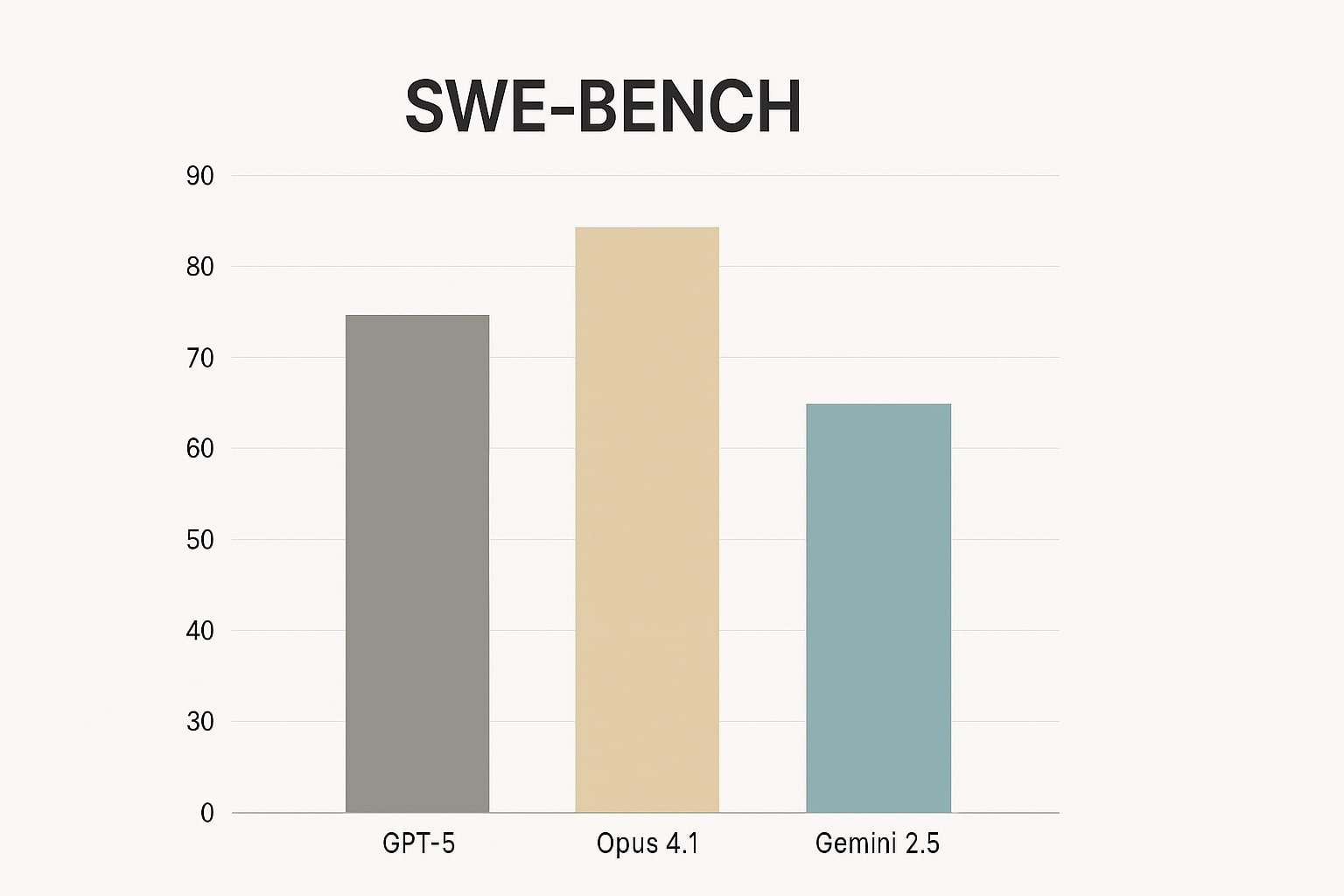
Ringkasan skor SWE-bench Verified tiga model
Titik tolak terbaik adalah metrik yang dekat dengan pekerjaan harian engineer, kemampuan memperbaiki isu nyata di repo terbuka dan lulus tes. SWE-bench Verified menjadi salah satu tool evaluasi publik yang semakin matang dan transparan metodologinya [10]. Sumber komunitas menyediakan ringkasan skor untuk orientasi cepat, namun keputusan final sebaiknya didukung shadow run pada repo internal karena perbedaan struktur dan kebijakan lint dapat memengaruhi hasil[3].
| Aspek | ChatGPT (GPT-5/Codex) | Claude Opus 4.1 | Gemini 2.5 Pro |
|---|---|---|---|
| Kekuatan utama | Pass@1 tinggi, alur PR review & saran berbasis diff [2] | Ketelitian agentik multi langkah, fokus coding nyata, tersedia via Claude Code, Bedrock, Vertex [1] | Ekosistem Google, kuat untuk agent setup di Code Assist & CLI, integrasi GCP/BigQuery [5][6] |
| Use case unggulan | Backend bugfix, refactor besar, PR review otomatis | Analisis bertahap, TDD terminal, iterasi UI teliti | Web dan data workflows di GCP, orkestrasi agen |
| Konteks & ingestion | Context window hingga ~400k, output besar untuk patch multi file [2] | Difokuskan untuk ketelitian agentik dan coding; efektif bila diberi peta dependensi serta file lint dan test [1] | Sinergi konteks dengan alat Google IDE, CLI, Vertex untuk proyek web dan data [5][6] |
| Tooling resmi | Codex CLI dan IDE, PR review serta saran berbasis diff [2] | Claude Code terminal dan IDE, mendampingi Opus 4.1 [1] | Gemini Code Assist VS Code dan JetBrains, Gemini CLI [5][6] |
| Harga API | Input ~$1.25/M, Output ~$10/M, cached input tersedia [4] | Sama seperti Opus 4 saat peluncuran Opus 4.1, rujuk kontrak harga Anda [1] | Berjenjang sesuai panjang prompt, context caching tersedia [6] |
| Privasi & enterprise | Zero Data Retention opsi untuk API bisnis [7] | Custom data retention di Enterprise, cakupan ZDR dijelaskan resmi [8][11] | Data governance Vertex AI untuk produk generatif [12] |
| Cocok untuk tim… | Yang mengejar time to merge singkat pada repo besar dan CI ketat | Yang butuh kualitas reasoning dan agentik tinggi dengan loop evaluasi | Yang hidup di ekosistem Google Cloud dan butuh integrasi ujung ke ujung |
Akurasi di benchmark vs ketahanan di produksi perusahaan
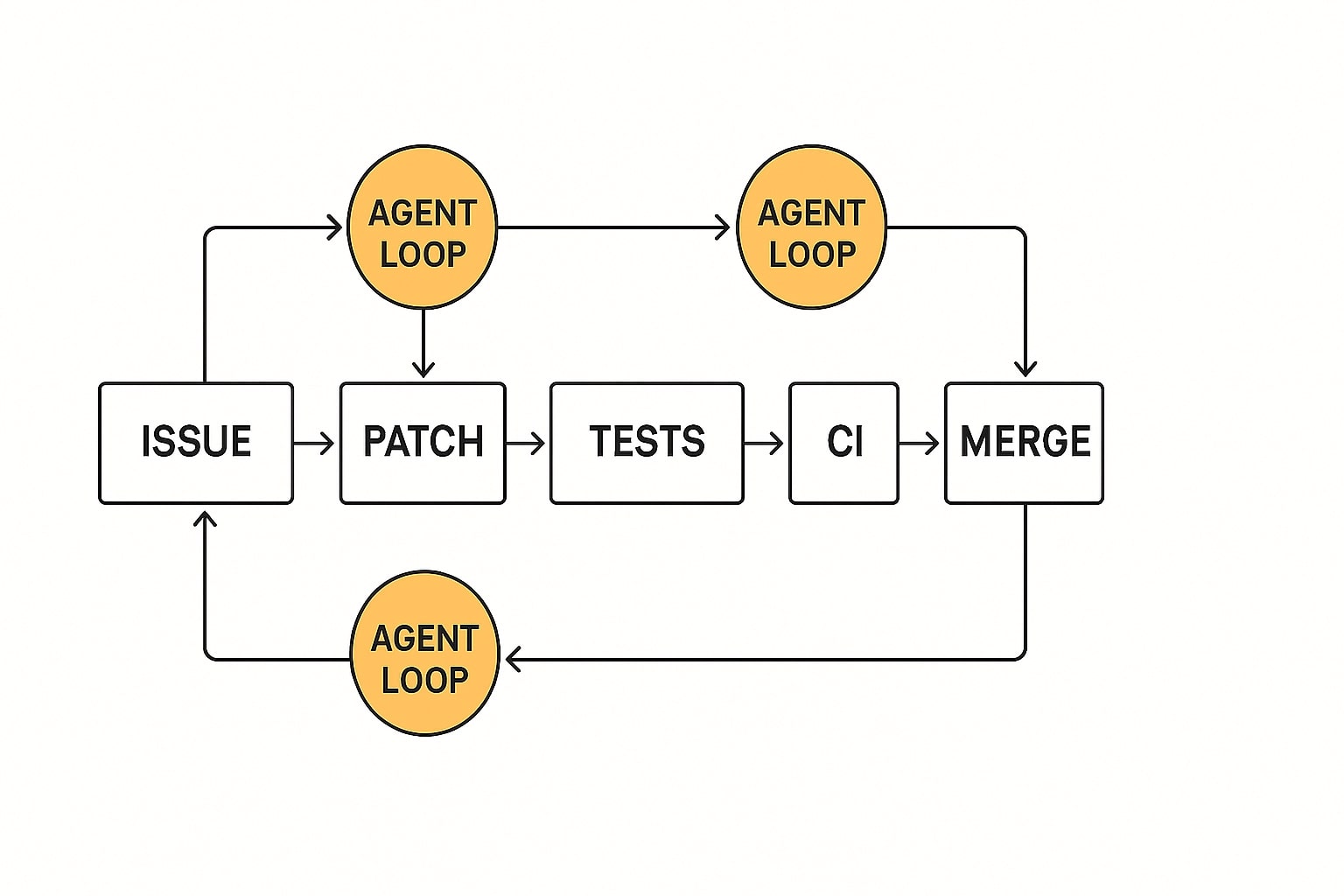
Dari isu ke patch, test, CI, PR, merge
Benchmark menyaring kandidat, namun produksi menambah variabel, struktur monorepo, flake tests, gaya linting, serta matrix versi dependensi. Di sini, kemampuan agen untuk merencanakan langkah, menjalankan tes, mengevaluasi diff, lalu memperbaiki diri menjadi pembeda. OpenAI memposisikan GPT-5 untuk coding dan tugas agentik dengan jalur PR yang rapi[2][4]. Anthropic merilis Opus 4.1 yang menekankan ketelitian multi langkah dan coding nyata, tersedia di API, Claude Code, Bedrock, dan Vertex AI[1]. Google mendorong praktik agent kustom lewat Gemini Code Assist dan Gemini CLI agar hasil konsisten di pipeline yang sama dengan IDE dan GCP[5][6].
Cara membaca hasil benchmark secara efektif
Gunakan skor publik sebagai prior, lalu replikasi pada subset isu internal dengan batas token dan waktu yang nyata. Sertakan retry budget, best of, dan pelaporan log yang membuat koreksi bisa ditindak pada sprint berikutnya[10].
Baca juga artikel menarik lainnya: Cara Mengoptimalkan Prompt ChatGPT, Gemini, dan Claude: Rahasia Tingkatkan Performa AI untuk Hasil Lebih Akurat
Kecepatan, biaya, dan efisiensi token dalam keputusan bisnis
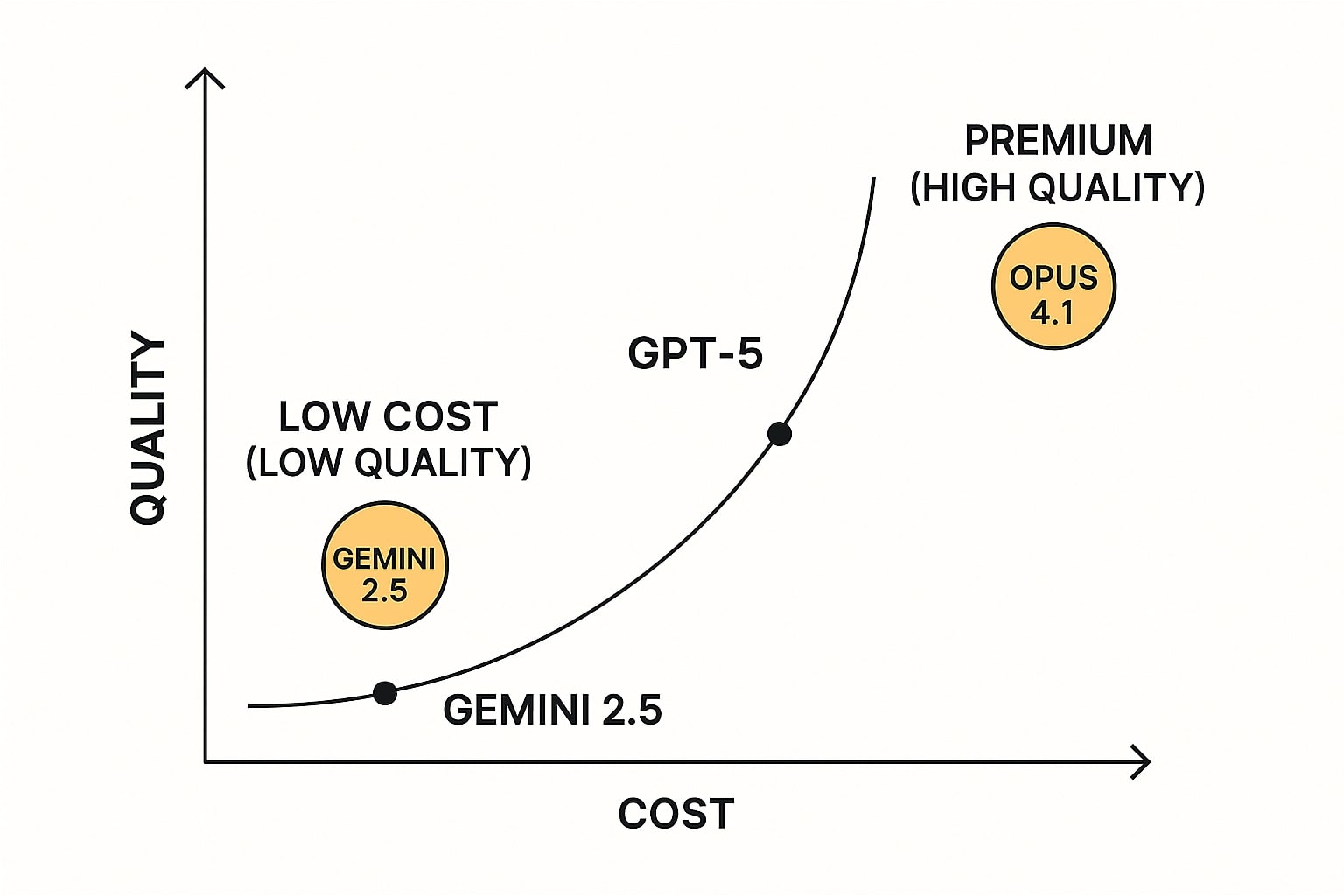
Trade off biaya dan pass rate
Biaya total CodeGen tidak hanya ditentukan harga per satu juta token, tetapi juga pola pemakaian, panjang dialog, serta retry. GPT-5 menampilkan harga resmi input sekitar 1,25 dolar dan output sekitar 10 dolar per satu juta token, ada opsi cached input untuk beban berulang [4]. Gemini 2.5 Pro memakai skema berjenjang, dokumentasi developer menjelaskan detail tier dan context caching [6]. Opus 4.1 diumumkan hadir dengan harga setara Opus 4 saat peluncuran sehingga tim yang sudah menghitung TCO Opus 4 dapat memakai perhitungan yang sama sebagai titik awal [1].
Kisaran harga resmi yang relevan
-
GPT-5, input ~$1.25/M, output ~$10/M, cached input tersedia [4].
-
Gemini 2.5 Pro, struktur harga per 1M token berbeda menurut panjang prompt, context caching tersedia [6].
-
Claude Opus 4.1, harga setara Opus 4 pada peluncuran, cek kontrak dan halaman rilis [1].
Kalkulator Simulasi Menghitung Biaya CodeGen
Kalkulator Biaya CodeGen
Masukkan parameter kerja Anda, hasil dalam USD. Verifikasi harga di halaman resmi vendor: OpenAI, Google Gemini, Anthropic.
Estimasi dipengaruhi input Anda; cek kembali harga di OpenAI, Google Gemini, dan pengumuman harga Anthropic terbaru.
Rekomendasi praktis, pilih model CodeGen sesuai pekerjaan mayoritas
Tidak ada satu model yang unggul di semua sumbu. Pilih satu model andalan sesuai pekerjaan mayoritas, lalu siapkan model pendamping untuk kasus khusus.
Backend bugfix dan PR review ketat, pilih GPT-5 + Codex untuk pass@1 tinggi dan alur diff dan PR yang siap ditindak [2][4].
Tugas agentik bertahap dan UI iteratif, pilih Claude Opus 4.1 + Claude Code, manfaatkan ketelitian dan pembacaan terminal yang rapi [1].
Tim GCP dan orkestrasi data, pilih Gemini 2.5 Pro + Code Assist dan CLI untuk sinergi BigQuery, Cloud Run, dan IDE [5][6].
Kapasitas konteks dan kerja lintas repo
.
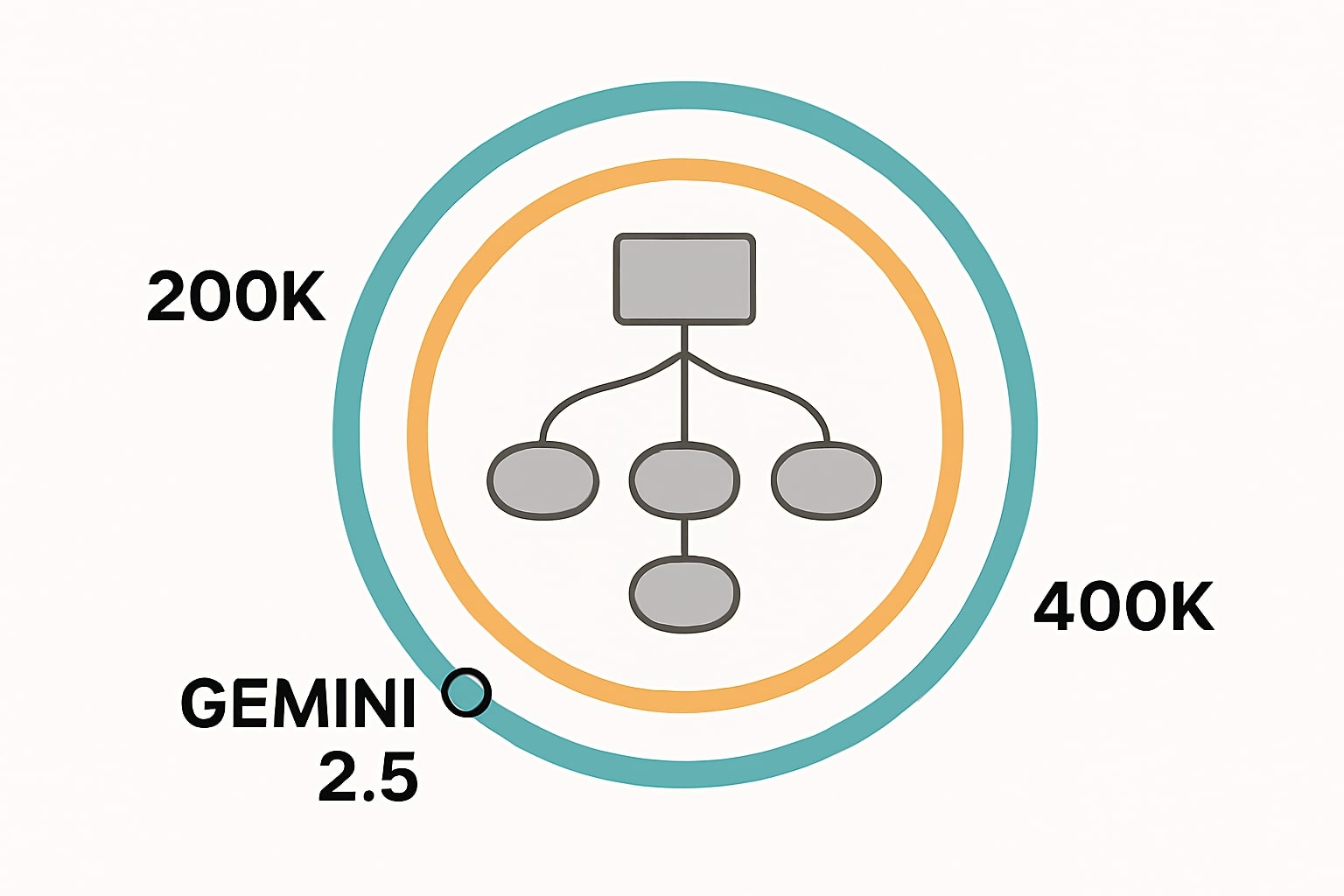
Dampak jendela konteks pada pemahaman codebase
Jendela konteks besar memudahkan ingestion banyak file sekaligus, namun tetap perlu kurasi. GPT-5 menyajikan context length hingga sekitar 400 ribu token dan output maksimum yang besar sehingga cocok untuk rancangan teknis panjang dan patch multi file [2]. Opus 4.1 difokuskan pada ketelitian agentik, efektif bila Anda menyuplai peta dependensi dan file konfigurasi lint dan test yang relevan [1]. Gemini 2.5 menyatu dengan alat internal Google dan alur kerja data aplikasi melalui Code Assist dan CLI [5][6].
Praktik konteks yang membantu agen memahami repo
Lakukan chunking per modul, sertakan tests, CI config, dan lint rules agar patch mengikuti gaya tim. Tambahkan ringkasan arsitektur, call graph, atau peta dependensi agar agen menavigasi cepat.
Tooling resmi dan ekosistem, Codex, Claude Code, Gemini Code Assist
CLI, IDE, PR review, dan agent mode
Tooling memengaruhi produktivitas harian, bukan hanya metrik akhir. OpenAI Codex menyertakan kemampuan PR review, saran berbasis diff, dan integrasi CLI serta IDE untuk alur dari prompt ke PR yang siap ditindak[2]. Claude Code mendampingi Opus 4.1, tersedia untuk pengguna berbayar dan nyaman untuk TDD, refactor, serta debugging berulang[1]. Gemini Code Assist dan Gemini CLI menghadirkan alur agen yang rapi di VS Code dan JetBrains serta integrasi langsung dengan GCP[5][6].
Integrasi IDE, CLI, dan CI yang mengurangi friksi
Aktifkan ekstensi IDE dengan aturan linting tim, siapkan pre commit hooks, serta templat PR yang mewajibkan diff summary dan hasil tes. Produktivitas agen naik signifikan ketika jalur otomatisasi dari patch ke PR mulus.
Contoh Kode CodeGen untuk ChatGPT, Claude Opus 4.1, dan Gemini
Snippet minimal tiga vendor, siap tempel
Penggunaan nyata dimulai dari snippet yang bisa ditempel. Saya siapkan pola prompt yang menekan halusinasi dan memaksa keluaran satu blok kode sehingga mudah dipakai di CI. Anda bisa mengganti task untuk Python, JavaScript, maupun CSS dengan struktur sama. Jalankan dari terminal, atau tempel di IDE, lalu integrasikan ke pipeline Anda[2][5][6].
ChatGPT Codex, OpenAI Responses API (Python)
from openai import OpenAI client = OpenAI() # OPENAI_API_KEY di environment task_py = ( "Tulis fungsi sliding_window_max(nums: list[int], k: int) " "lengkapi docstring Google style, type hints, dan uji unit singkat." ) prompt = f"""Anda adalah asisten CodeGen tingkat senior, keluarkan hanya satu blok kode Python tanpa penjelasan. Tugas: {task_py} Persyaratan: - Type hints, docstring Google style. - Satu uji unit dengan unittest. Output: satu blok kode saja. """ resp = client.responses.create( model="gpt-5-codex", input=prompt, temperature=0.2, max_output_tokens=1200, ) print(resp.output_text)
ChatGPT Codex, OpenAI Responses API (JavaScript ESM)
import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY }); const taskJs = "Buat util debounce(fn, wait) dengan AbortController; sertakan JSDoc dan contoh uji Vitest singkat."; const prompt = `Anda adalah asisten CodeGen tingkat senior, keluarkan hanya satu blok kode JavaScript tanpa penjelasan. Tugas: ${taskJs} Persyaratan: format ESM, JSDoc, contoh uji Vitest singkat. Output: satu blok kode saja.`; const resp = await client.responses.create({ model: "gpt-5-codex", input: prompt, temperature: 0.2, max_output_tokens: 1200, }); console.log(resp.output_text);
Anthropic Claude Opus 4.1, Messages API (Python)
from anthropic import Anthropic client = Anthropic() # ANTHROPIC_API_KEY di environment system = ("Anda adalah asisten CodeGen senior. Keluarkan hanya satu blok kode tanpa penjelasan. " "Gunakan standar industri dan konsistensi format.") task_js = ("Implementasikan library kecil 'memoize' untuk fungsi murni dengan TTL opsional, " "sertakan JSDoc dan contoh uji Vitest singkat.") resp = client.messages.create( model="claude-opus-4.1", max_tokens=1400, system=system, messages=[{"role": "user", "content": task_js}], temperature=0.2, ) print(resp.content[0].text)
Anthropic Claude Opus 4.1, Messages API (JavaScript)
import Anthropic from "@anthropic-ai/sdk"; const anthropic = new Anthropic({ apiKey: process.env.ANTHROPIC_API_KEY }); const system = "Anda adalah asisten CodeGen senior. Hanya satu blok kode tanpa penjelasan."; const taskPy = "Tulis modul Python 'url_slugify' dengan type hints dan uji pytest singkat."; const resp = await anthropic.messages.create({ model: "claude-opus-4.1", max_tokens: 1400, system, messages: [{ role: "user", content: taskPy }], temperature: 0.2, }); console.log(resp.content[0].text);
Google Gemini 2.5 Pro, Generative AI API (Python)
import os, google.generativeai as genai genai.configure(api_key=os.environ["GEMINI_API_KEY"]) model = genai.GenerativeModel("gemini-2.5-pro") task_css = ("Tulis CSS navbar responsif, gunakan variabel CSS, container queries, " "tema terang dan gelap, komentar bagian utama.") resp = model.generate_content( task_css, generation_config={"temperature": 0.2, "max_output_tokens": 1200} ) print(resp.text)Google Gemini 2.5 Pro, Generative AI API (JavaScript)
import { GoogleGenerativeAI } from "@google/generative-ai"; const genAI = new GoogleGenerativeAI(process.env.GEMINI_API_KEY); const model = genAI.getGenerativeModel({ model: "gemini-2.5-pro" }); const taskPy = "Tulis fungsi Python 'top_k_frequent' dengan docstring Google dan uji pytest singkat."; const res = await model.generateContent({ contents: [{ role: "user", parts: [{ text: taskPy }] }], generationConfig: { temperature: 0.2, maxOutputTokens: 1200 } }); console.log(res.response.text());Tips: gunakan temperature rendah, minta satu blok kode saja, sediakan unit test singkat agar keluaran langsung dipakai CI.
Metodologi Evaluasi dan Repro Guide untuk Perbandingan CodeGen
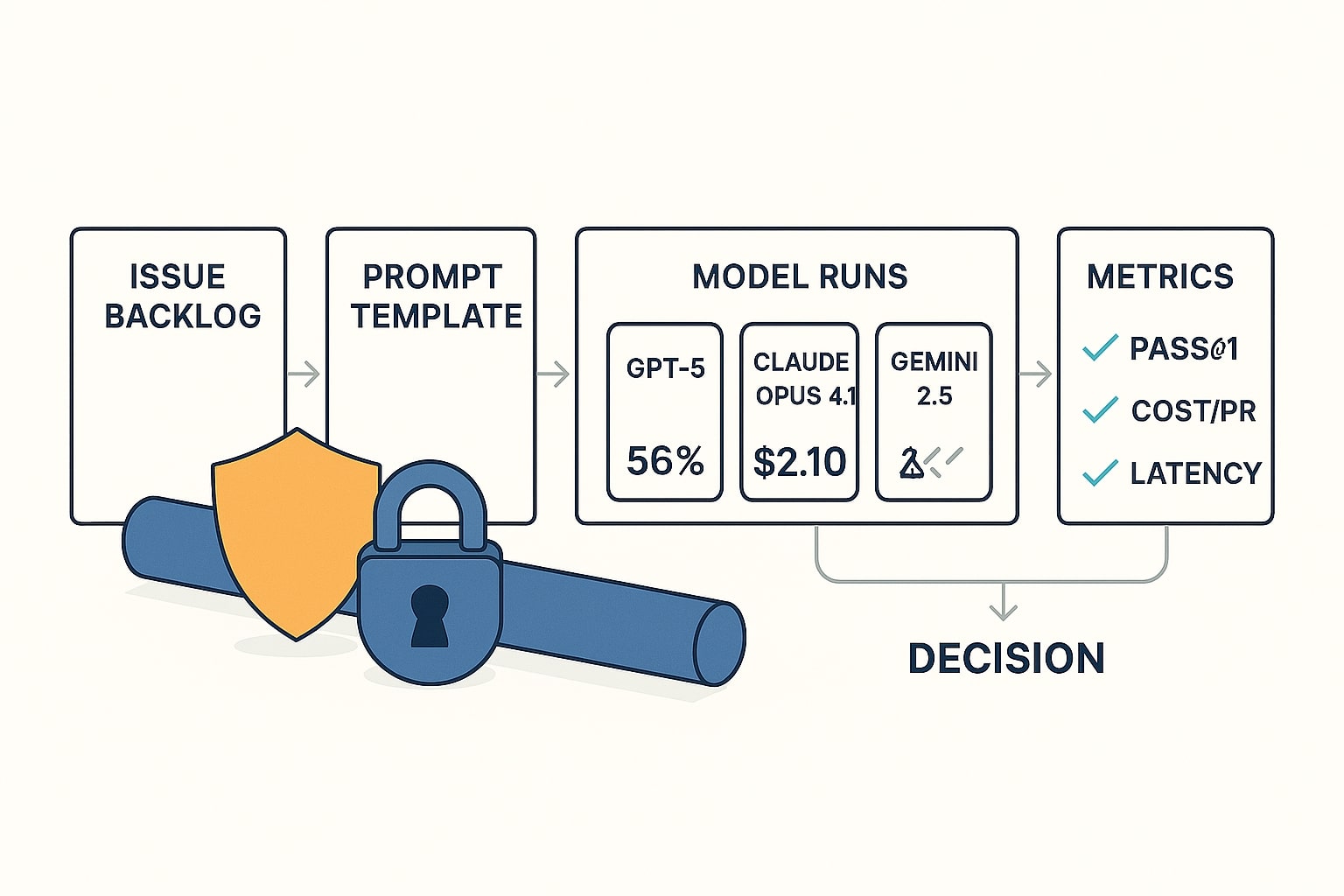
Diagram metodologi evaluasi dan alur replikasi, dari isu hingga verifikasi hasil.
Keputusan teknis yang kuat lahir dari metodologi yang bisa direplikasi. Saya memakai tolok ukur yang dekat dengan realita, SWE-bench Verified sebagai jangkar publik dan uji bayangan internal pada subset isu tim Anda [10]. Metrik yang dicatat meliputi pass@1, biaya per PR yang benar benar lulus, waktu patch sampai merge, serta kepuasan developer karena faktor ergonomi sangat mempengaruhi adopsi [3].
Ruang lingkup dan metrik
-
Cakupan, bugfix nyata, refactor terarah, penambahan test bila perlu
-
Metrik, pass@1, biaya per PR lulus, latensi eksekusi, kepuasan dev
-
Batasan, variasi monorepo, flake tests, kebijakan lint berbeda
H3 — Panduan replikasi 10 menit
- Siapkan repo uji kecil beserta tests, CI config, dan aturan lint.
- Pasang tiga provider client dan kunci API di environment.
- Tempel prompt template yang memaksa keluaran satu blok kode.
- Jalankan tiga model pada isu yang sama, simpan log, diff, dan hasil test.
- Catat token input dan output, ulang jika perlu dengan retry budget tetap.
Pemetaan Use Case ke Model CodeGen
Matriks sederhana mempercepat keputusan karena mengikat tujuan dengan alat. Isi sesuai prioritas tim Anda, lalu revisi tiap kuartal.
| Use case | Model utama | Model pendamping | Alasan singkat |
|---|---|---|---|
| Bugfix backend, PR ketat | GPT-5 Codex | Opus 4.1 | Pass@1 dan alur PR review kuat [2] |
| Refactor UI, iterasi teliti | Opus 4.1 | GPT-5 | Ketelitian agentik multi langkah [1] |
| Data dan aplikasi di GCP | Gemini 2.5 Pro | GPT-5 | Sinergi Code Assist, CLI, Vertex [5][6] |
| PR review otomatis | GPT-5 Codex | Gemini 2.5 Pro | Saran berbasis diff dan PR siap tindak [2] |
| TDD di terminal | Opus 4.1 + Claude Code | GPT-5 Codex | Nyaman untuk loop uji beruntun [1] |
Failure Modes dan Debugging Guide
Kegagalan umum bersifat berulang sehingga respons cepat bisa diotomasi.
-
Import halusinasi, injeksikan daftar dependensi valid ke konteks
-
Patch tidak lolos lint, sertakan aturan lint dan pre commit
-
Test flaky, set seed tetap dan jalankan ulang dengan log diagnostik
-
Versi dependensi salah, kunci versi di lockfile dan cantumkan di konteks
-
Output melebar, pakai temperature rendah dan batasi format ke satu blok kode
Keamanan dan Tata Kelola yang Praktis
Audit singkat mencegah masalah di hilir. Gunakan tabel ini untuk tim legal dan security.
| Aspek | OpenAI | Anthropic | Google Cloud |
|---|---|---|---|
| Retensi data | Opsi ZDR API bisnis [7] | Retensi kustom Enterprise [8] | Tata kelola Vertex AI [12] |
| Pelatihan pada data | Non default untuk API bisnis, sesuai perjanjian | Sesuai kontrak Enterprise | Sesuai DPA Google Cloud |
| Lokasi pemrosesan | Lihat dokumen privasi bisnis | Lihat dokumen privasi Enterprise | Kontrol pelanggan di dokumen Vertex |
| Audit dan akses | Log, peran, kebijakan internal | Log, SSO, audit Enterprise | IAM, audit, kebijakan GCP |
Cakupan ZDR untuk produk berbasis API key komersial dijelaskan resmi oleh Anthropic [11].
Panduan Integrasi IDE, CLI, dan CI/CD
Waktu developer turun ketika jalur otomatisasi rapi dari prompt hingga PR.
-
IDE, aktifkan Codex, Claude Code, atau Code Assist sesuai langkah vendor [2][1][5]
-
CLI, siapkan environment terpisah per vendor, token aman, dan project id
-
CI, tambahkan job yang memanggil agen, jalankan test, lampirkan ringkasan ke PR
-
PR template, wajibkan diff summary, file terubah, hasil test, dan risiko
-
Observabilitas, simpan token usage, latensi, dan pass@1 per PR
Contoh Playbook Shadow Run 14 Hari yang Eksekutabel
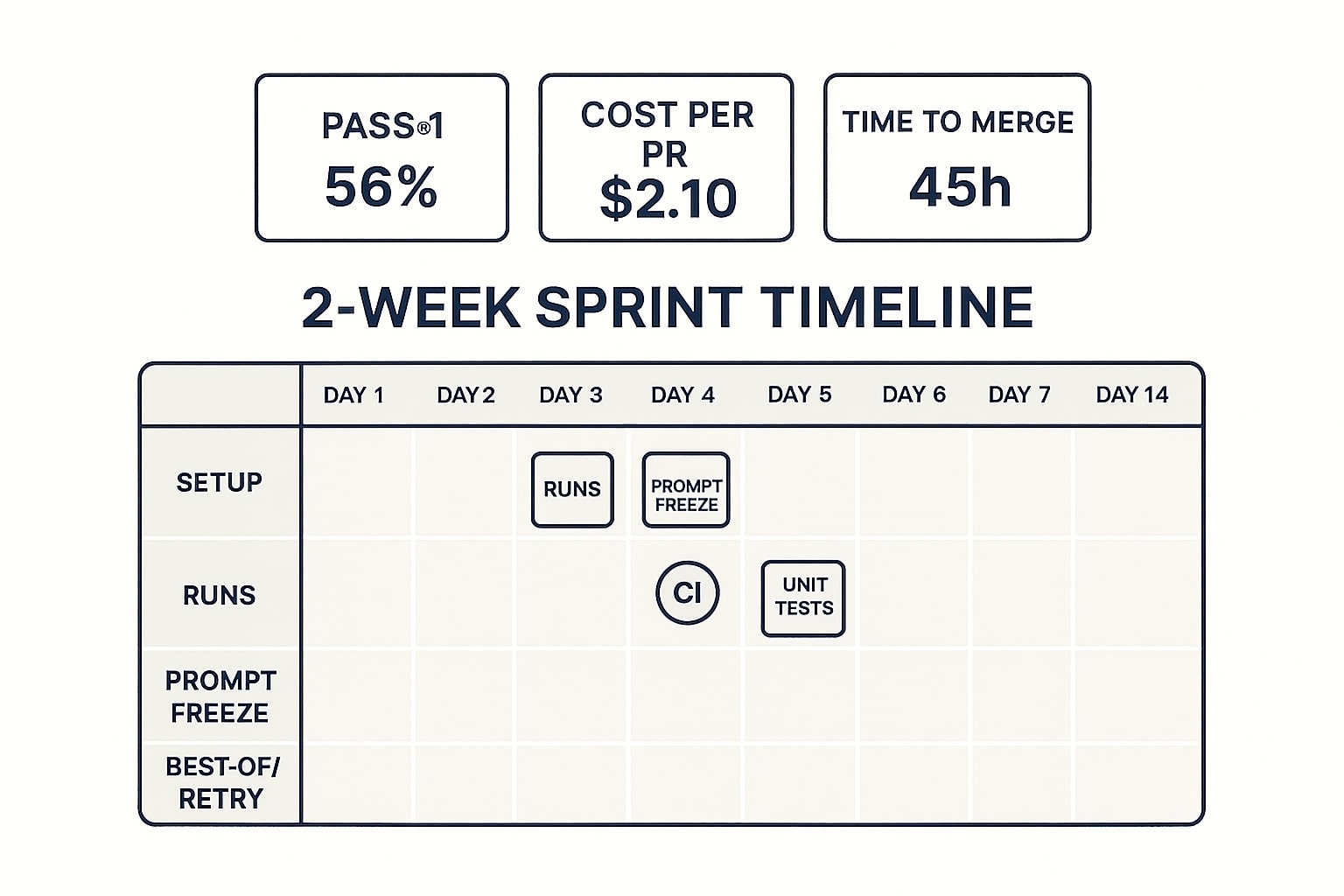
Papan rencana dua minggu, eksperimen terstruktur dengan KPI yang bisa ditindak.
Dua minggu sudah cukup untuk mengubah rasa penasaran menjadi angka yang bisa ditindak. Fokus pada tugas representatif, bukan demo yang terlalu mudah, tetapkan retry budget serta best of yang realistis.
Minggu 1, eksplorasi terkendali
-
Hari 1 sampai 2, siapkan repo uji, prompt template, logging, dan scorecard
-
Hari 3 sampai 4, jalankan tiap model pada sepuluh isu prioritas
-
Hari 5 sampai 7, perbaiki prompt, observasi latensi, evaluasi pass@1
Minggu 2, konsolidasi dan simulasi produksi
-
Hari 8 sampai 10, bekukan prompt, aktifkan pre commit hooks, PR template
-
Hari 11 sampai 12, simulasi best of dan retry sesuai anggaran
-
Hari 13 sampai 14, ringkas metrik, pilih model andalan, tetapkan model pendamping
Roadmap Adopsi CodeGen di Tim Engineering Anda
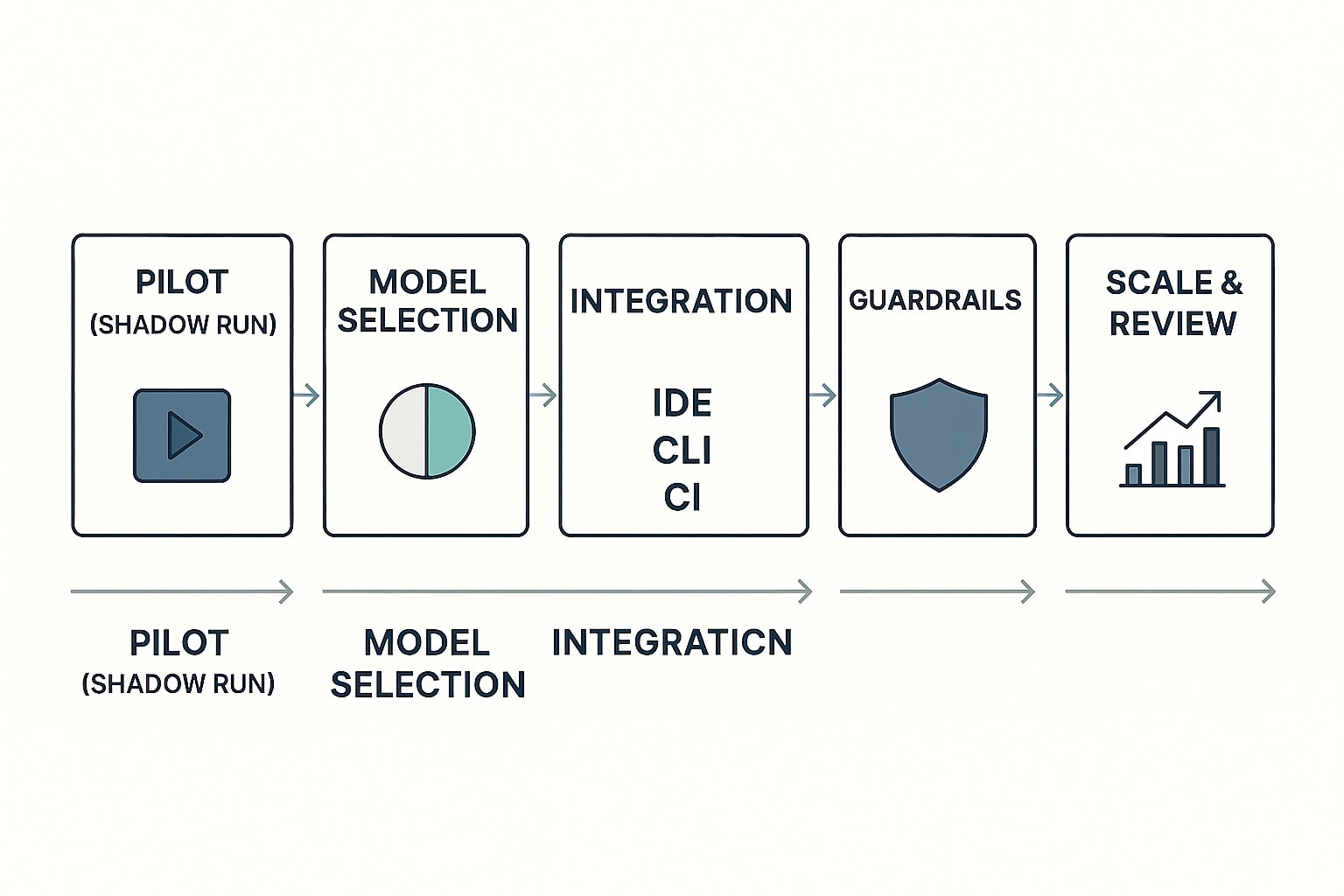
Langkah adopsi dari uji bayangan hingga standardisasi model di CI/CD.
Mulai dengan shadow run selama dua minggu agar keputusan berbasis data, bukan asumsi. Tetapkan metrik yang bisa ditindak, pass@1, biaya per PR yang lulus, waktu patch sampai merge, dan kepuasan developer. Kunci keputusan pada pekerjaan mayoritas, lalu tetapkan aturan kapan memakai model pendamping. Jika Anda punya pengalaman atau pertanyaan implementasi, tinggalkan komentar, saya akan bantu mengarahkan eksperimen berikutnya agar lebih efektif pada sprint mendatang.
References
- Anthropic — Claude Opus 4.1, rilis dan ketersediaan API, Claude Code, Bedrock, Vertex AI ↩
- OpenAI — GPT-5, konteks besar dan alur PR untuk coding ↩
- LLM-stats — Ringkasan SWE-bench Verified untuk orientasi ↩
- OpenAI — API Pricing resmi untuk model GPT ↩
- Google Cloud — Gemini Code Assist overview ↩
- Google — Gemini Developer API Pricing dan context caching ↩
- OpenAI — Business data privacy dan Zero Data Retention untuk API ↩
- Anthropic — Custom data retention controls untuk Enterprise ↩
- Anthropic — Halaman model Opus sebagai penerus Opus 4 ↩
- SWE-bench — Metodologi dan viewer leaderboard Verified ↩
- Anthropic — Cakupan Zero Data Retention untuk produk berbasis API key ↩
- Google Cloud — Vertex AI generative data governance ↩

