Essence: Agentic prompting is the 2025 instruction language for complex code generation, where models plan, act with tools, and self critique against a rubric.
- Real world impact, SWE bench results improved and developer AI adoption keeps rising [Stanford AI Index 2025, Stack Overflow Survey].
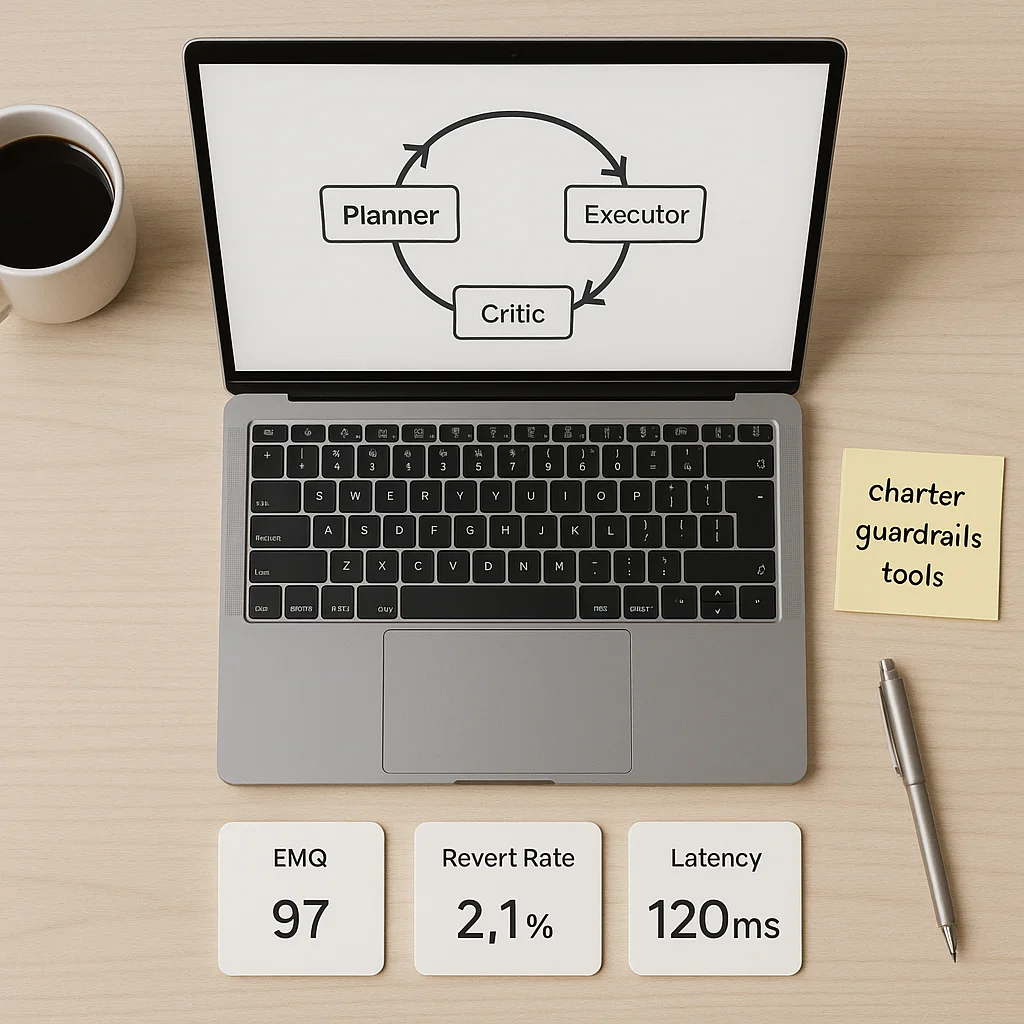
- Working architecture, write an Agent Charter and a rubric, then run a Planner, Executor, Critic loop with small diffs and fast tests.
- Tooling, publish tool contracts via the Model Context Protocol, orchestrate with LangGraph, pair with repo aware IDE assistants [MCP spec, LangGraph docs].
- Safety, enforce directory boundaries, secret handling, stop conditions, and guardrail tests in risky scenarios [Claude Computer Use, Gemini Computer Use].
- Measurement, track EMQ, revert rate, unit test pass rate, latency p95, and reviewer minutes per pull request for continuous evaluation.
Agentic Prompting in 2025, what it is and why it works
Agentic prompting is a structured way to tell a coding model what outcome to achieve, which tools to call, how to plan the work, and when to stop. The approach fits the moment, this year most developers report using AI tools in their workflow and over half of professionals use them daily, a sharp rise that signals new habits forming in the editor and the terminal [1].
The capabilities of coding models also moved quickly. Stanford’s AI Index shows performance on the SWE-bench benchmark jumping from about four percent in 2023 to more than seventy percent in 2024, a result that redefined expectations for autonomous patching and multi step reasoning on real issues [2].
Benchmarks do not write production code by themselves, yet they reveal a pattern, models that can reason, plan, and act with tools tend to unlock more of that performance on real repositories. Public leaderboards like SWE-bench and SWE-bench Verified illustrate the rise of agent frameworks and planners that call tools, run tests, and refine patches based on observations [3].
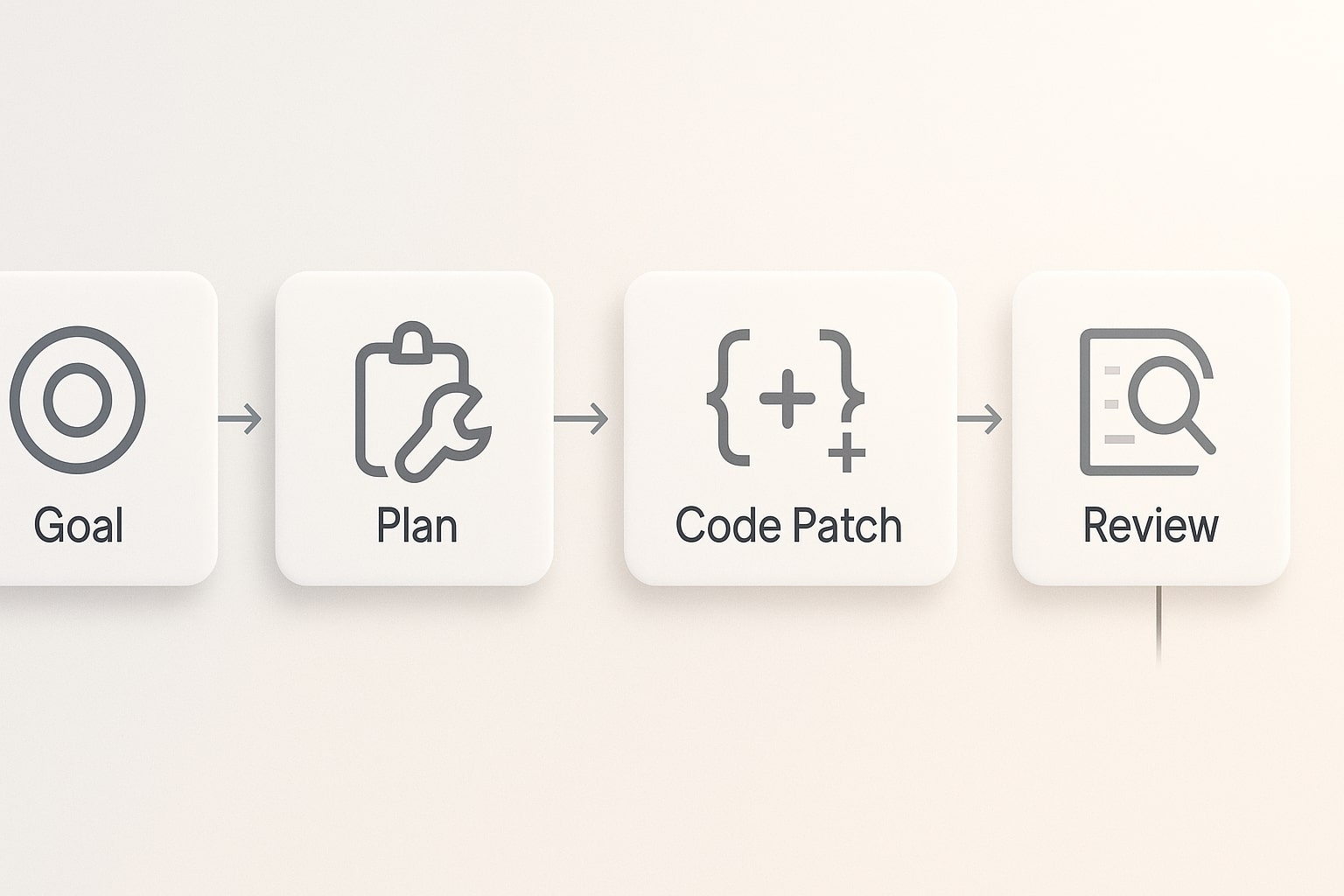
Core patterns for complex code generation with agentic prompting
Before commands and code, a clear description helps the model choose a path. Three sentences to set the stage often pay off, the model understands the business goal, the constraints, and the stop conditions. Then patterns take over, each pattern aligns the conversation with a known control structure.
-
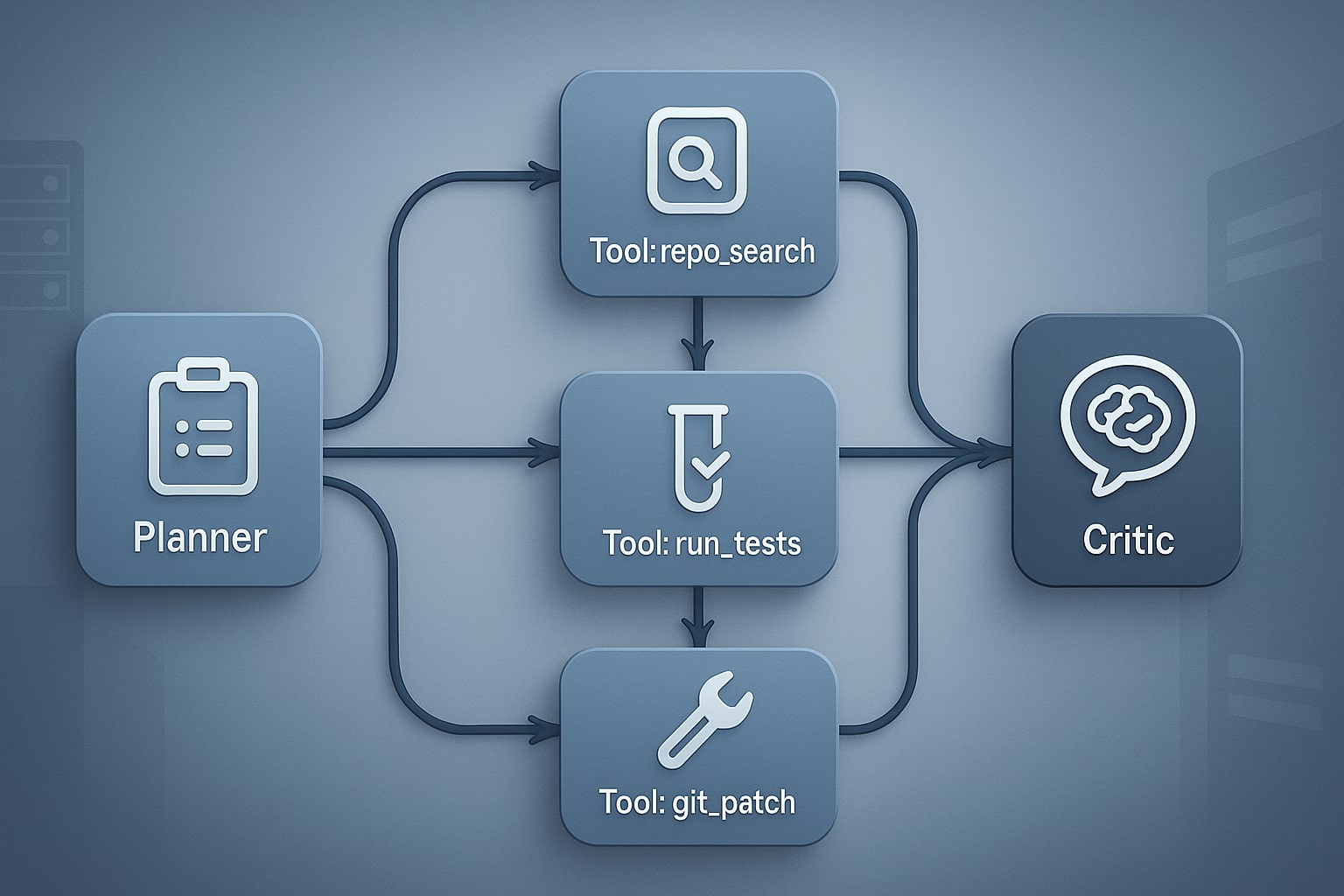
Planner, Executor, Critic loop. Ask the model to propose a numbered plan with risks, implement the next step as a minimal diff, run tests, then critique and decide to continue or escalate.
-
ReAct style trace. Use a cycle of Thought, Action, and Observation to keep state explicit and auditable for each step of the task [4].
-
Rubric first. Provide pass and fail criteria before the first token of code, for example unit tests that must pass, files that must not change, and a size limit for diffs.
-
Tool contract. Describe each tool with inputs, outputs, failure modes, and timeouts, so the model can plan accurately and recover from errors.
-
Counterfactual plan. Ask the model to list what could go wrong, then add checks for each risk, such as running a subset of slow tests or placing logs behind a feature flag.
These patterns came from the research line that blends reasoning with acting, notably the ReAct paper that connected latent reasoning with tool calls and environment feedback [4].
Check out this fascinating article: The Ultimate AI Agent Tools and Frameworks Comparison Guide for 2025: Which Solution Is Right for You?
Write the Agent Charter, objectives, guardrails, and interfaces
A good charter reads like a one page contract between you and your agent. Three parts make it practical for code work.
Mission and success. Name a business outcome and a measurable result, for example reduce checkout errors by ten percent through input validation on the server route, success when error rate drops for two consecutive days.
Scope and guardrails. List allowed repositories and paths, style rules, secrets policy, and a clear stop condition, for example touch only apps/cart and libs/validators, never print secrets, stop if tests fail twice in a row.
Interfaces and metrics. Define where the agent appears, chat in the IDE, a CLI, or a CI job, and what to measure, EMQ score, unit test pass rate, revert rate, latency p95. This makes review and rollback a first class path rather than an afterthought.
Copy ready Charter block
Mission target outcome and success metric, Scope allowed code paths, Capabilities planning, tool use, critique, tests, Guardrails secrets policy and file boundaries, Interfaces IDE chat and CI job, Metrics EMQ and revert rate, Stop Conditions failing tests or low confidence.
From single prompt to multi stage plans, planner, executor, and critic
Agentic prompting treats planning as a separate product of the model. Ask for a plan first, ask for a risk table next, only then ask for code. The executor step applies the smallest patch that moves the plan forward and immediately runs tests, the critic compares results to the rubric and either continues or asks a question.
Example scaffolding, ready to paste.
-
Planner, list numbered steps, files to touch, tests to run, and a risk for each step, low, medium, or high.
-
Executor, propose a unified diff for step one with a short commit message, then run the fast tests and summarize failures.
-
Critic, score the patch against the rubric, if score is below the threshold, list defects and propose the next patch, if score meets the threshold, stop and request review.
This structure pairs well with LangGraph, a low level orchestration framework that represents agent flows as nodes with explicit state, which improves debuggability and reliability for long running work [8].
Tool use and the Model Context Protocol for safe power
Agentic prompting shines when the model can reach your tools. In 2025, the Model Context Protocol provides a standardized way to expose tools and resources, the community calls it a universal connector for AI apps [6].
OpenAI’s developer resources describe MCP servers that publish tool schemas and results, while clients request actions through a well defined exchange, this removes glue code and makes multi model setups easier to manage [7].
Major providers now ship agentic computer use as an explicit capability. Anthropic documents a desktop style environment where Claude can operate applications with defined safety layers, a beta that matured through 2025 with a strong focus on guardrails [4][14].
Google introduced Gemini 2.5 Computer Use for browser and mobile control with developer documentation and an API path through Google AI Studio and Vertex AI, this targets tasks that lack direct programmatic access [5].
MCP style tool note: Put the tool schema in front of the model, not behind a hidden wrapper, so the agent can plan with accurate constraints and error messages, then log each tool call with inputs, outputs, and duration for your scorecard.
Check out this fascinating article: Agentic AI Workflows: Replace $50K/Year Virtual Assistant with n8n Automation
Agentic prompting across leading tools and IDE assistants in 2025
Agentic workflows do not require a single vendor. Many teams combine a planner executor loop with an IDE assistant. Prices change, yet a comparison helps shape budgets and pilots. The table summarizes individual or per user plans and the features that matter for agentic code work.
Price comparison and focus, October 2025
| Tool | Price, plan | Notable agentic traits | Source |
|---|---|---|---|
| GitHub Copilot Pro | 10 USD per month, individual, Copilot Pro Plus listed at 39 USD | Chat in IDE and web, repo aware context, ecosystem with PR summaries | [9] |
| Cursor Pro | 20 USD per month, Pro Plus at 60, Teams at 40 | Cursor Rules, repo map, deep codebase awareness, fast planner feel | [10] |
| Amazon Q Developer Pro | 19 USD per user per month, includes allocations for agentic requests and code transforms | Agentic coding in IDE and CLI, pooled limits, clear data controls | [11] |
| Windsurf, Codeium | Free for individuals, enterprise plans available | Project wide context, chat and search, growing flow features | [12] |
| JetBrains AI Assistant | 100 USD per year for AI Pro, listed by JetBrains | Deep IDE integration across IntelliJ family and fleet | [13] |
Pricing and plan names reflect the provider pages captured in October 2025, check the linked pages for current terms.
This ecosystem view fits a practical rule, pilot with one assistant that matches your stack and repository size, then layer LangGraph or your chosen runtime for the long running Planner, Executor, Critic loop, and keep the MCP tools shared so different models can use them.

Hands on practice, build a reliable code generation agent in ninety minutes
Goal. Add server side input validation to an existing checkout route without breaking analytics or logging.
Setup. Choose any assistant from the table, prepare a small repo with a failing test that represents the desired behavior, and expose three tools through MCP or your framework, repo_search, git_patch, run_tests.
Step 1, write the Agent Charter.
Mission, reduce checkout errors by ten percent through validation, Scope, only apps/cart and libs/validators, Guardrails, no secrets in logs and a change size limit, Interfaces, IDE chat and CI job, Metrics, EMQ and revert rate, Stop conditions, two test failures in a row or low confidence.
Step 2, provide a rubric first.
Functional tests must pass, only approved paths change, naming follows style, logs at debug level not info. Ask the model to restate the rubric before any code and to stop if a rule appears impossible.
Step 3, plan the work.
Prompt, show a numbered plan with files, tests, and risks. Ask for a commit message for each patch and a rollback note when risk is medium or high.
Step 4, execute with tests.
Prompt, apply step one as the smallest possible unified diff, then run fast tests, report results, and propose a second patch only if the rubric still passes.
Step 5, critique and decide.
Prompt, score the patch against the rubric, list defects and fixes, and either continue the loop or request a human review with a summary.
Why this works. The plan creates a contract, the executor keeps changes small, and the critic prevents silent failure by comparing results to explicit pass and fail signals.
Tip: If the model wanders, ask it to print the current plan and show which step it believes it just completed, then reconcile with the Git diff and the test results.
Risk management, evaluation, and red teaming for agentic code
Real world code has sharp edges. Plan for three classes of risk with concrete checks.
Security and privacy. Forbid secrets in logs, limit file system access, and isolate tokens. MCP and similar protocols publish tool boundaries and help reduce accidental sprawl, watch for prompt injection through tool outputs and register only the tools you need [6].
Runaway edits. Add a size limit for diffs, require unit tests to pass before the next patch, and stop after two consecutive failures. Store every tool call with inputs and outputs so reviewers can trace a problem.
Measurement drift. Create a small scorecard that tracks EMQ, revert rate, and review minutes per pull request. Treat red team prompts as a product, include misleading file names, near match symbols, and ambiguous specifications, then record how the agent responds.
Starter pack: The download includes a CSV scorecard and a ready to paste rubric, use them to set baselines and watch trends as adoption grows.
Operational playbook, where agentic prompting creates value
Agentic prompting is not a replacement for design or deep reviews, it is a way to move common change classes with clarity and speed. Teams report the most value in maintenance tasks, safe refactors with guardrails, test creation and triage, reusable validation or serialization, and small feature flags that ride behind tests. When the problem is novel, the agent becomes a planning partner that proposes options and helps with scaffolding.
Adoption keeps rising even as trust remains mixed, surveys show a majority use AI tools while many still want human oversight and curated data. That tension is healthy, use agentic prompting to encode your standards, not to skip them [1].
Free Download — Agentic Prompting 2025 Starter Pack
Launch a reliable agentic coding flow in under 90 minutes, with an Agent Charter and rubric, MCP style tool contracts, Planner, Executor, Critic prompts,
LangGraph style skeletons for Python and TypeScript, plus a Google Sheets KPI dashboard and evaluation scorecard.
- Agent Charter & Rubric templates, quickstart and checklist
- MCP tool contracts for repo_search, git_patch, run_tests
- Planner, Executor, Critic prompt library, reviewer checklist
- LangGraph style skeletons, Python and TypeScript
- Google Sheets v5 template with KPI Dashboard, Pivot Views, Charts, target lines
Download Google Sheets Template
Updated: October 29, 2025, license: MIT, verify assistant pricing on vendor pages before purchase.
Use it as a launchpad, then share what worked and what needs improvement in the comments.
References
- Stack Overflow Developer Survey 2025 — AI usage
- Stanford AI Index 2025 — Technical performance highlights
- SWE-bench — Official leaderboards and docs
- ReAct, Synergizing Reasoning and Acting in Language Models
- Google, Introducing Gemini 2.5 Computer Use
- Model Context Protocol, 2025 specification
- OpenAI, MCP overview in the Apps SDK
- LangGraph, low level orchestration for stateful agents
- GitHub Copilot plans and pricing, Pro and Pro Plus
- Cursor pricing page, Pro, Teams, Pro Plus
- Amazon Q Developer FAQs and pricing, Pro tier nineteen USD
- Windsurf, formerly Codeium, pricing for individuals
- JetBrains AI Assistant pricing
- Anthropic, Claude Sonnet 4.5 announcement
Ready to apply this to your business?
Let's Talk Strategy →