Table of Contents
- What You Will Build and Why It Matters
- System Architecture for an AI Customer Service Assistant with Claude and n8n
- Setting Up n8n for Production Reliability
- Provisioning Claude API and Picking the Right Model
- Designing a Trustworthy System Prompt and Guardrails
- Building the Workflow in n8n, Step by Step
- Retrieval Augmentation, Your Facts not the Model’s Hunches
- Adding Multichannel Connectors without Rewriting Your Core
- Evaluation, Monitoring, and Cost Control
- Build a Ground Truth Evaluation Set and QA Rubric
- Trace Log Schema, SQL example, and Sheet structure
- Security, Privacy, and Responsible Use
- Incident Response Runbook for CX Assistants
- A Minimal Working Example you can copy
- Scaling Beyond the Prototype, with Confidence
- Turning This Blueprint into Daily Customer Wins
Margabagus.com – Response time shapes trust, revenue, and retention. In the latest CX trendlines, a large majority of service leaders plan to adopt or pilot customer-facing generative AI within the 2025 planning horizon, and many already report efficiency gains across digital touchpoints.[1] I want you to build an assistant that actually answers correctly, routes edge cases, and lowers average handle time without risking your brand. The stack here is deliberately pragmatic, I use n8n for orchestration and the Claude API for reasoning so you can pilot in days, not quarters. Claude’s Messages API is stable, versioned through headers, and supports models tuned for conversational support with tool use and large context windows when you need them.[2]
Across teams that adopt similar patterns, you see three results that matter to the business, faster first response, higher self-serve deflection, and tighter escalation loops. Zendesk’s recent CX analyses report most CX leaders see generative AI improving efficiency per interaction, and frontline employees say decision support from AI improves their work quality.[3] When you and I design the workflow well, that efficiency shows up as deflected tickets and fewer context switches for agents, not as brittle chat scripts.
What You Will Build and Why It Matters
This AI Customer Service Assistant is designed to receive customer messages from a chosen channel, validate and enrich them, retrieve relevant facts from a knowledge base, leverage Claude to draft the best response, and then reply on the original channel while creating or updating a help-desk ticket when necessary. The entire process will be implemented as an n8n workflow with clear nodes to ensure full traceability for every message.
The core of the assistant is Claude’s Messages API. It is called with a system prompt to frame its role, a user message containing the query and context, and specific token and safety parameters. The call uses the anthropic-version header, a specific model name, and a sensible max_tokens value—an approach that is reliable and easy to maintain.
n8n serves as the automation backbone, offering webhooks, credential management, access control (RBAC), and native nodes for Anthropic, Notion, Google Sheets, Slack, and Zendesk. Consequently, the need for glue code is minimized, and development cycles are faster.[4]
System Architecture for an AI Customer Service Assistant with Claude and n8n
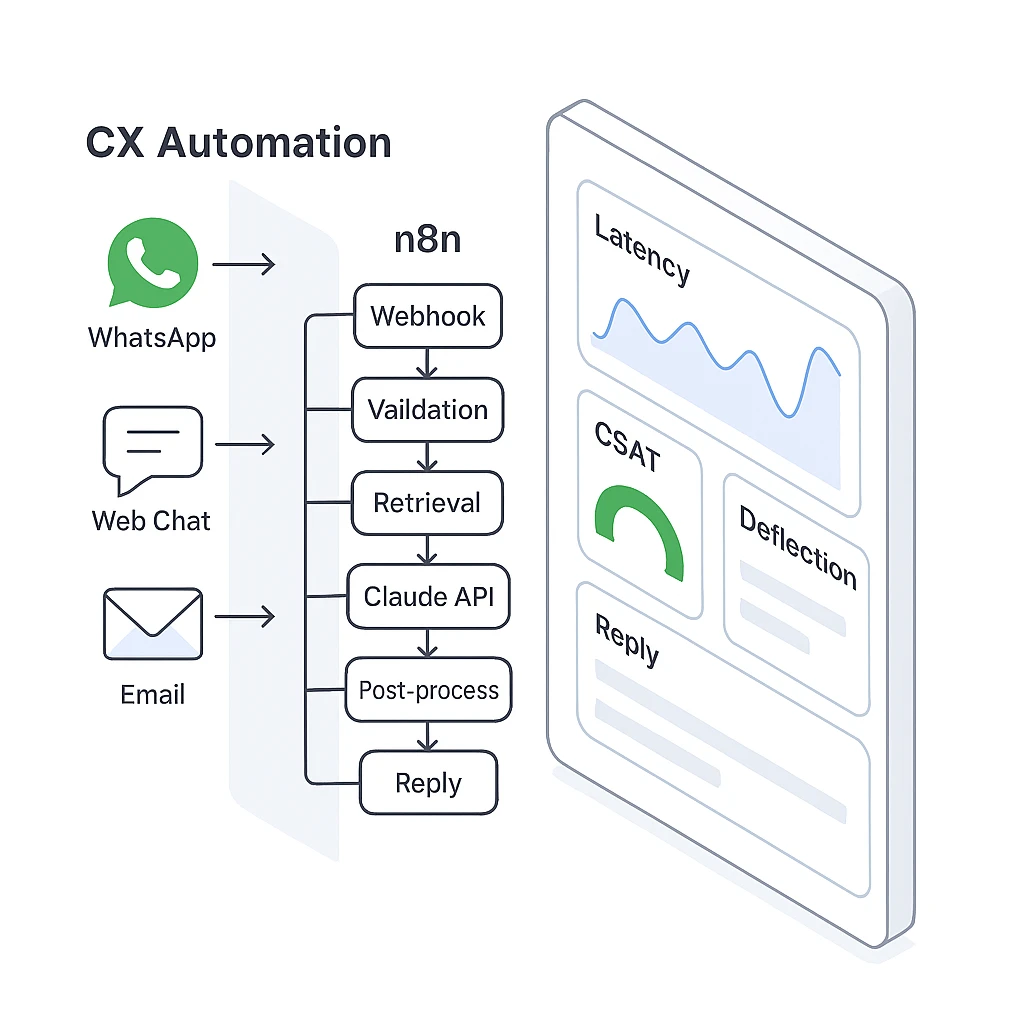
End-to-end flow from inbound message to reply and ticket creation
At a glance, the flow looks like this, Channel → n8n Webhook → Validation & Enrichment → Retrieval → Claude Messages API → Channel Reply & Ticketing → Logs & Metrics. This architecture favors observability and safe fallbacks. You can swap channels without touching your core logic and you can scale horizontally by adding webhook workers when volume rises.[5]
Key components and roles
-
Inbound channels: WhatsApp Cloud API, web chat, Slack, or email. Each channel hits an n8n Webhook or a channel-specific Trigger node.[6]
-
n8n orchestrator: Handles auth, mapping, enrichment, RAG, retries, logging, and tickets. Use Credentials, Environment Variables, and RBAC for secure operations.[7]
-
Claude API: Answers with reasoning grounded in retrieved context, using the Messages endpoint with your system prompt and guardrails.[2]
-
Help desk: Create or update tickets in Zendesk when confidence is low or when policy requires human approval.[8]
-
Storage & analytics: Persist logs to Sheets or a database, monitor SLA, accuracy, and deflection.[9]
Setting Up n8n for Production Reliability
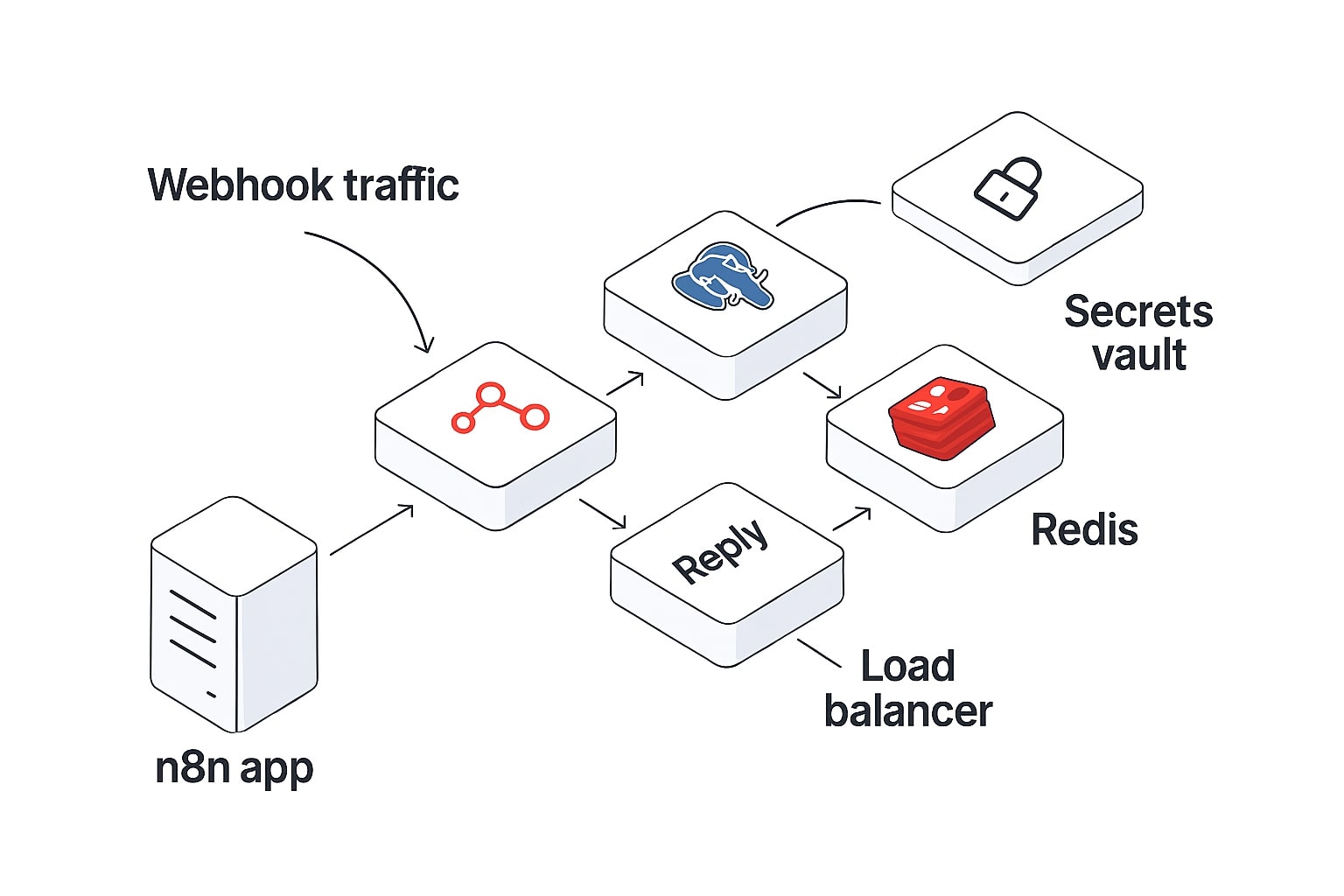
Production-ready n8n with PostgreSQL, Redis queue mode, and secure credential storage
You can start with Cloud or self-hosted. For self-hosting, configure environment variables for credentials, database, and endpoints. By default n8n uses SQLite, switch to PostgreSQL for production, and prefer queue mode with Redis for scale, which decouples webhook reception from workflow execution.[10]
Credentials and secrets. Use n8n’s Credentials UI or environment-variable overrides. You can keep sensitive values in mounted files with the _FILE pattern and restrict access via RBAC. OAuth is preferred where available.[7]
Webhooks. The Webhook node gives you separate test and production URLs, ideal for staging rollouts. Return a JSON body from the workflow to behave like an API endpoint for your chat frontend.[11]
Backups and operations. Nightly backups and container-side copy jobs are recommended. As traffic grows, dedicate instances for webhooks and scale workers based on queue depth.[12]
Check out this fascinating article: Voice AI Sales Funnel: n8n + Eleven Labs for Automated Lead Qualification
Provisioning Claude API and Picking the Right Model
Create an API key in the Anthropic Console, then call POST /v1/messages with headers x-api-key and anthropic-version: 2023-06-01. Choose a current model string such as claude-sonnet-4-20250514 or your preferred stable identifier, set max_tokens, and include your messages array.[2]
Rate limits and quotas. Claude enforces request and token rate limits. Plan for retries with backoff on 429 and design your workflow to budget tokens across input and output, since Anthropic maintains separate input and output token limits on the Messages API.[13]
Context windows. For everyday CX tasks, the standard 200k context window on 3.5-class models is plenty, but if you need huge document packs, Claude Sonnet 4 offers a 1 million token context window on the API, currently via a beta header for long-context usage tiers.[14]
Designing a Trustworthy System Prompt and Guardrails
Your system prompt should define tone, boundaries, and escalation rules. Keep role in system, put task and retrieved facts in the user turn, and avoid cramming everything into the system field, Anthropic recommends that split for control and clarity.[15]
To align with responsible use, reflect policy items like no speculative medical or legal advice and a bias toward handoff when confidence is low. Anthropic publishes usage policy updates and safety guidance that you can mirror in your prompt, and its customer-support guide shows practical steps for guardrails in support contexts.[16]
Building the Workflow in n8n, Step by Step
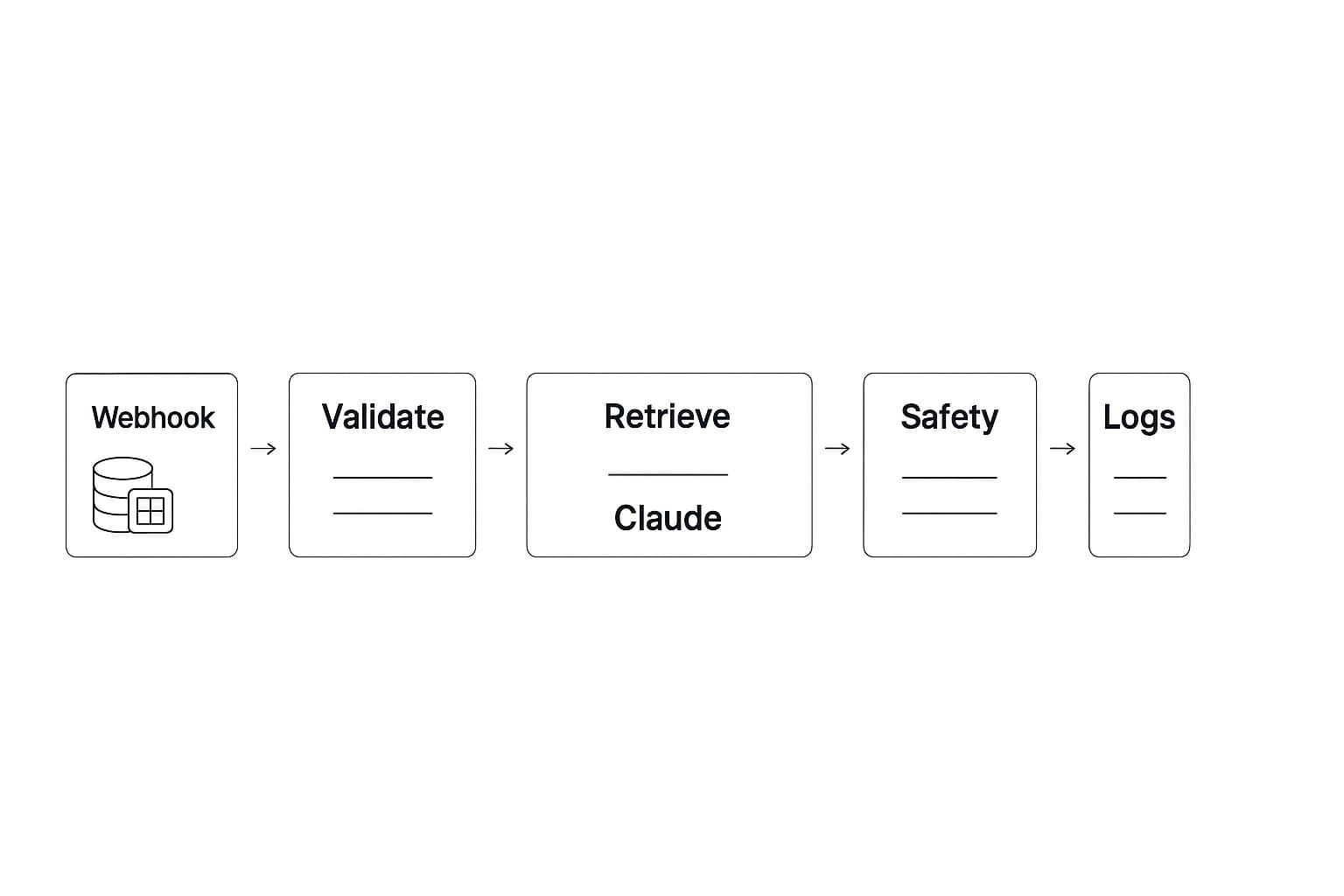
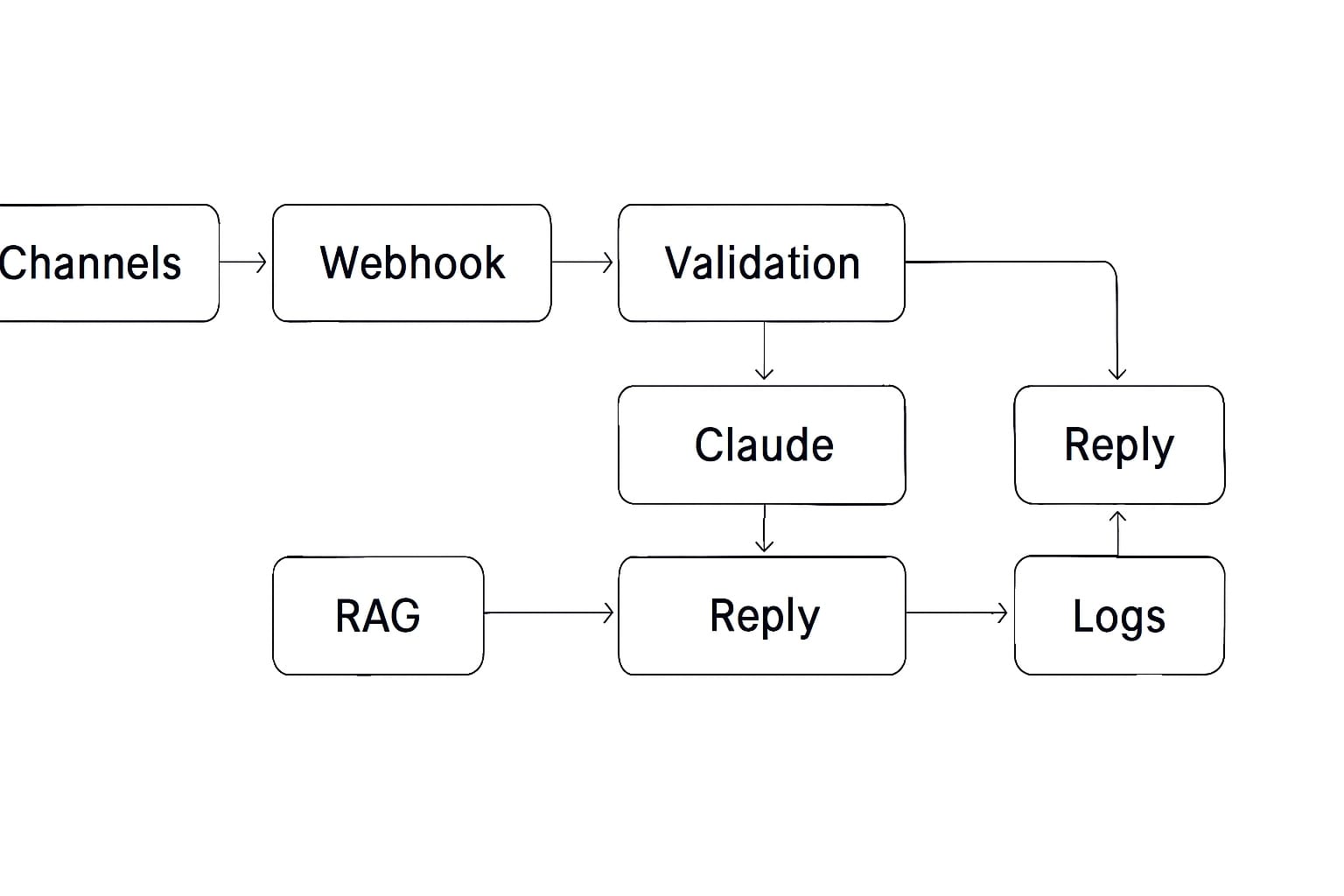
Node map from Webhook to Logs
Below is a minimal but production-ready pattern. I write this so you can paste values and ship quickly.
1) Trigger
-
Node: Webhook (Production URL)
-
Method:
POST -
Payload:
{ channel, user_id, message, metadata } -
Docs: Webhook node supports test and production URLs and can return response data.[11]
2) Validate and normalize
-
Node: Function
-
Trim whitespace, enforce maximum message length, reject empty payloads, detect language and channel. Add a
trace_id.
3) Retrieve knowledge
-
Node options:
4) Compose the message for Claude
-
Node: Set
-
System: “You are a customer support AI for COMPANY. Always ground answers in the provided facts, cite policy titles, never invent order numbers, and hand off when confidence is low or when messages include PII or billing disputes.”
-
User: Include the customer message and the retrieved facts in a structured format with clear separators.
5) Ask Claude
-
Node A: Anthropic node in n8n, or
-
Node B: HTTP Request with
POST https://api.anthropic.com/v1/messages-
Headers:
x-api-key,anthropic-version: 2023-06-01,content-type: application/json -
Body:
{ "model": "claude-sonnet-4-20250514", "max_tokens": 700, "messages": [ ... ] }[2]
-
6) Safety and confidence checks
-
Node: Function
-
If Claude indicates uncertainty or a policy keyword is present, set
needs_handoff = true.
7) Reply on the original channel
-
WhatsApp: call WhatsApp Cloud API
/messageswith a text reply or template[6] -
Slack: post a message with thread context[19]
-
Email: send a templated response or queue for human review[20]
8) Ticketing
-
Zendesk: create or update a ticket with the conversation transcript, tags for intent, and
trace_id. Use the Tickets API Create endpoint[8]
9) Logging and analytics
-
Sheets or DB: log
trace_id, latency, token counts, Claude stop_reason, confidence, channel, and deflection flag. This gives you service analytics without another tool.[9]
Retrieval Augmentation, Your Facts not the Model’s Hunches
The answers grounded in your policies and current information. With n8n you can query Notion or Google Sheets before calling Claude, then pass the answers as structured context. Keeping facts separate avoids bloating the system prompt and reduces token waste.[17]
Design your KB schema with intent, pattern, answer, policy_reference, last_updated. During retrieval, prefer exact policy snippets so Claude can quote titles or sections, which improves trust. n8n nodes cover Sheets and Notion well, and you can always fall back to an HTTP Request if you need a custom query.[9]
Adding Multichannel Connectors without Rewriting Your Core
Multiple channels into one workflow
WhatsApp Cloud API sends messages through the /PHONE_NUMBER_ID/messages endpoint for text, media, and interactive templates, perfect for order status and policy replies.[8]
Slack Web API lets you reply in threads using chat.postMessage with an OAuth token. The official docs detail channel handling for public channels, private channels, and DMs.[12]
Email works well for fallback acknowledgments when a chat channel is down. Use a consistent subject prefix and include the trace_id for easy correlation in your logs.
Check out this fascinating article: Agentic AI Workflows: Replace $50K/Year Virtual Assistant with n8n Automation
Evaluation, Monitoring, and Cost Control
Define KPIs you and I can track from day one, first response time, resolution rate without agent, handoff rate, CSAT, and token cost per conversation. Log token usage and latency per step. Anthropic exposes input and output token rate concepts and request IDs, so add those to your logs for capacity planning and traceability.[13]
Plan for 429 and transient errors with exponential backoff. Keep max_tokens conservative, and budget tokens for the retrieval context so costs do not spike. If you need long documents in context, consider the 1M context window on Sonnet 4 only for specific flows, then cap usage using workflow conditions.[14]
Build a Ground Truth Evaluation Set and QA Rubric
Purpose
You and I want measurable evidence that the assistant answers correctly, respects policy, and improves operations.
Size and composition
Use thirty to fifty real conversations from your main channel, with a balance of routine questions, tricky edge cases, and adversarial prompts such as PII requests or refund outside policy.
Dataset template (Sheets or CSV)trace_id, timestamp, channel, user_text, language, intent_gold, kb_snippet_gold, expected_policy_ref, should_handoff (y/n), expected_outcome (answer|handoff|ticket), notes
Scoring rubric (0–5, weighted)
Factuality 30%, Policy adherence 20%, Task completion 20%, Handoff quality 10%, Tone and clarity 10%, Latency perception 10%.
Interpretation, 4.5–5 ready to scale, 4.0–4.49 solid with minor tuning, 3.5–3.99 improve retrieval and the system prompt, <3.5 fix guardrails and update the KB.
Weekly QA loop
Sample twenty recent conversations, score, capture the top five fixes, update KB and prompts, retest ten conversations, track deltas.
Trace Log Schema, SQL example, and Sheet structure
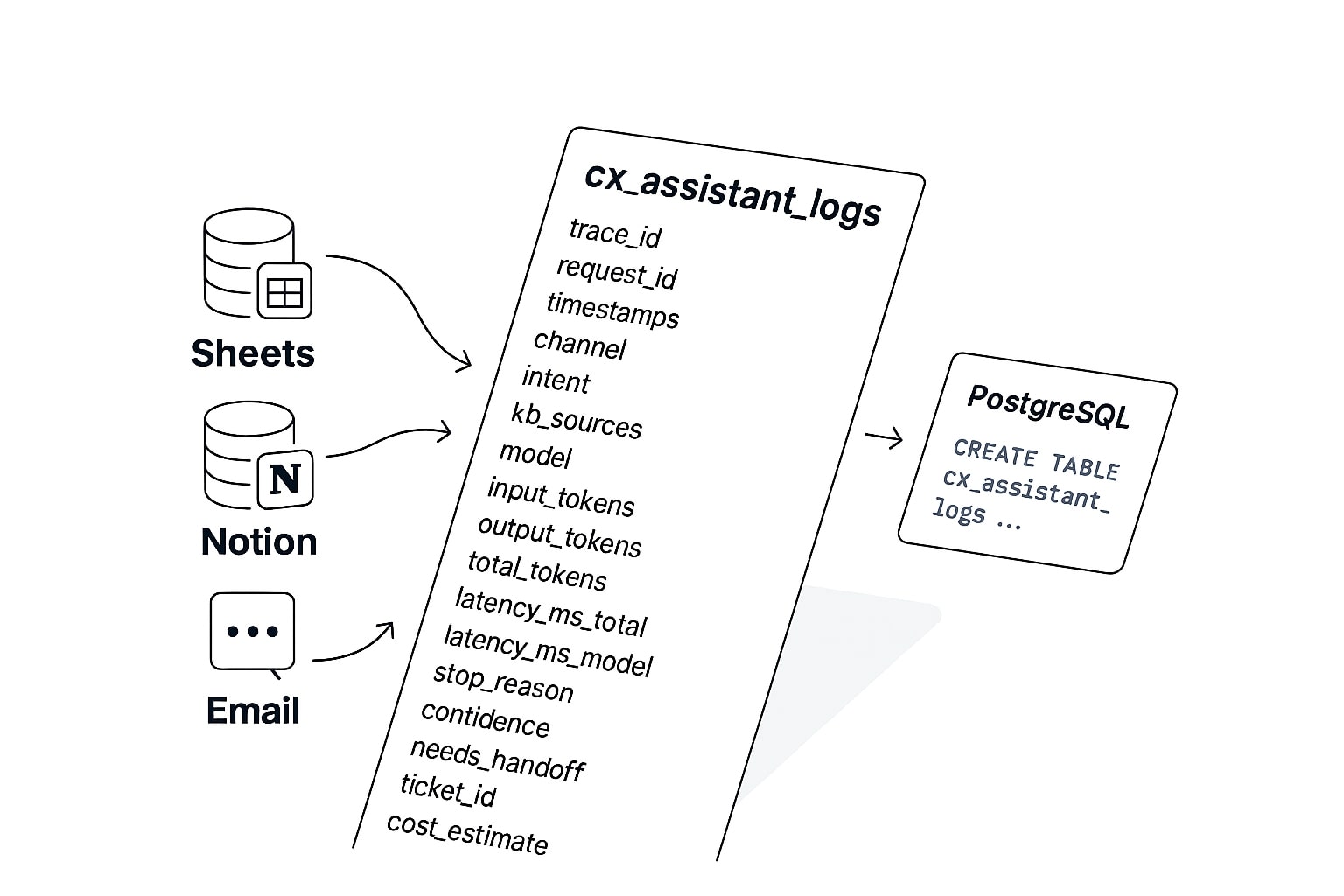
Trace log schema and SQL fields for observability, cost attribution, and debugging
Why logging matters
You cannot improve what you cannot see. The schema below gives you visibility into tokens, latency, decisions, and cost.
Required columnstrace_id, request_id, timestamp_start, timestamp_end, channel, user_id_hashed, intent, language, kb_sources, model, input_tokens, output_tokens, total_tokens, latency_ms_total, latency_ms_model, latency_ms_retrieval, stop_reason, confidence, needs_handoff, ticket_id, deflected, cost_estimate
PostgreSQL table
CREATE TABLE cx_assistant_logs ( id BIGSERIAL PRIMARY KEY, trace_id TEXT NOT NULL, request_id TEXT, timestamp_start TIMESTAMPTZ NOT NULL, timestamp_end TIMESTAMPTZ NOT NULL, channel TEXT, user_id_hashed TEXT, intent TEXT, language TEXT, kb_sources TEXT, model TEXT, input_tokens INT, output_tokens INT, total_tokens INT, latency_ms_total INT, latency_ms_model INT, latency_ms_retrieval INT, stop_reason TEXT, confidence NUMERIC(3,2), needs_handoff BOOLEAN DEFAULT FALSE, ticket_id TEXT, deflected BOOLEAN DEFAULT FALSE, cost_estimate NUMERIC(10,4) ); CREATE INDEX ON cx_assistant_logs (timestamp_start); CREATE INDEX ON cx_assistant_logs (trace_id); CREATE INDEX ON cx_assistant_logs (intent);Single CSV example rowtrace_01,req_abc,2025-09-17T12:05:11+07:00,2025-09-17T12:05:13+07:00,whatsapp,usr_xxx,refund_policy,id,"Policies!A12:B20",claude-sonnet-4-20250514,610,280,890,2100,1500,300,stop_sequence,0.86,false,,true,0.0231
Security, Privacy, and Responsible Use
Store all secrets in n8n Credentials and consider file-based _FILE mounts for sensitive values. Use role-based access control, enforce MFA or SSO, and prefer OAuth scopes where possible. n8n publishes security and compliance guidance and supports RBAC on paid plans.[7]
For channels, WhatsApp Cloud API requires a phone number ID and supports text, media, and interactive messages via the /messages endpoint.[8] For ticketing, Zendesk offers a comprehensive Ticketing API with create and update operations documented in the reference and quick start.[9]
On the model side, align prompts and workflows with Anthropic’s Usage Policy and customer-support guardrails. Avoid collecting unnecessary PII, remove card or bank numbers, and route disputes or account takeovers to a human. Anthropic publishes policy updates and support-specific guides that you can mirror in your governance docs.[16]
Incident Response Runbook for CX Assistants
Rate limits from the model
Immediate action, retry with exponential backoff, reduce max_tokens, buffer traffic through the queue. Mitigation, smooth bursts, budget tokens per intent, log vendor request IDs for audit.[2]
Channel outage, WhatsApp or Slack unavailable
Immediate action, send an email acknowledgment that the message is received and will be answered, create a high priority incident log. Mitigation, add health checks every minute and run a secondary webhook instance behind the load balancer.[6]
Unexpected cost spike
Immediate action, trim retrieval context and reduce max_tokens, gate long context paths behind conditions. Mitigation, daily cost reports per channel, threshold alerts.
Hallucination or policy violation
Immediate action, enable conservative prompt mode and force human handoff on sensitive categories. Mitigation, expand KB coverage and maintain a keyword block list.
Knowledge drift
Immediate action, hotfix the specific KB row and tag it for further review. Mitigation, weekly KB reviews with last_updated and owner fields.
Latency spikes
Immediate action, cache frequent retrieval results and ensure queue mode is on. Mitigation, autoscale workers by queue depth and dedicate instances for webhooks.[6]
Internal communication protocol
Use a Slack channel named cx-assistant-incident. Status format, When, Impact, Suspected cause, Actions, ETA, Next update in. Run a post-incident review within twenty four hours and store it in Notion.
A Minimal Working Example you can copy
Claude API cURL
Use this to sanity-check credentials and model selection before wiring n8n:
curl https://api.anthropic.com/v1/messages \ -H "x-api-key: $ANTHROPIC_API_KEY" \ -H "anthropic-version: 2023-06-01" \ -H "content-type: application/json" \ -d '{ "model": "claude-sonnet-4-20250514", "max_tokens": 700, "messages": [ {"role": "system", "content": "You are a helpful customer support AI for COMPANY. Answer only with facts from the provided context. Escalate when unsure."}, {"role": "user", "content": "Customer question: {{text}}\n\nContext:\n{{kb_excerpt}}"} ] }'Scaling Beyond the Prototype, with Confidence
As volume grows, put n8n in queue mode with Redis, move webhooks to dedicated instances, and autoscale workers based on queue size. These patterns are widely recommended in community and deployment guides for bursty inbound traffic.[12]
For deep troubleshooting or large account migrations, selectively enable 1M context windows on Sonnet 4 only for investigative flows. Keep policy checks strict, and continue to log token use per conversation for cost governance.[14]
If you need extra reliability in regulated contexts, align with n8n security guidance and your own data retention policy. Stick to minimal PII in prompts, rotate keys, and audit credentials after role changes.
Turning This Blueprint into Daily Customer Wins
Turn the blueprint into daily results, ship, observe, iterate
You and I share the same goal here, fast, factual answers that respect policy and hand off gracefully. Ship the minimal path first, observe real conversations, then tune retrieval and prompts. If any step feels uncertain, add a human handoff rule and keep trust as the default. I would love to hear how your pilot goes, what customers ask most, and where you want the assistant to grow, leave a comment or a question so we can iterate together.
References
- Gartner — Customer service AI use cases and 2025 adoption signals ↩
- Anthropic — Claude API Messages reference and headers ↩
- Zendesk — AI customer service statistics 2025 and CX Trends ↩
- n8n Docs — Anthropic node for Claude integration ↩
- n8n Community — Best practices for scaling webhooks and workers ↩
- Meta — WhatsApp Cloud API /messages reference ↩
- n8n — Security, RBAC, OAuth guidance ↩
- Zendesk — Tickets API ↩
- n8n Docs — Google Sheets node for logging and KB ↩
- n8n Docs — Database environment variables, PostgreSQL for production ↩
- n8n Docs — Webhook node, test and production URLs ↩
- n8n Docs — Backups and deployment notes ↩
- Anthropic — Rate limits and token budgeting ↩
- Anthropic — Claude Sonnet 4 now supports 1M token context window ↩
- Anthropic — System prompt tips for role vs task ↩
- Anthropic — Usage policy update and responsible use ↩

